
MMVCを導入することで、自分の声を「ずんだもん」に変えたり、「四国めたん」などにすることができます。MMVCを使用することで、オンラインゲームでのプレイやボイスチャットでのコミュニケーションがより楽しくなることでしょう。しかし、初めてボイスチェンジャーを導入する人にとっては、何から始めたら良いのかわからないかもしれません。この記事では、MMVCを導入するための基本的な情報から、設定方法、使い方、まで、初心者でも分かりやすく解説していきます。
2023年3月5日に作成した記事なので最新版とは異なる可能性があります。
MMVCとは
MMVCとは、天王洲アイル様が開発した、リアルタイムで音声を変換するボイスチェンジャーソフトです。機械学習技術によって、リアルタイムで誰でも好きな声に変換できます。声質変換には、例えば「ずんだもん」「四国めたん」「九州そら」「春日部つむぎ」などのキャラクターボイスにも対応しています。MMVCは、Google Colaboratoryを使って簡単に機械学習の学習フェーズを実行することができるため、個人の環境に依存せずに利用することができます。
利用規約やガイドラインに従い、安全かつ適切に利用するよう注意してください。
「好きな声に」という点は、「権利・規約で問題ないなら」という注意点があります。
「MMVC」「VOICEVOX」利用規約
MMVCの導入方法
解説がかなり長くなってしまいましたがこの記事で導入から使用まで出来るようになるのでぜひMMVCを楽しんでください。
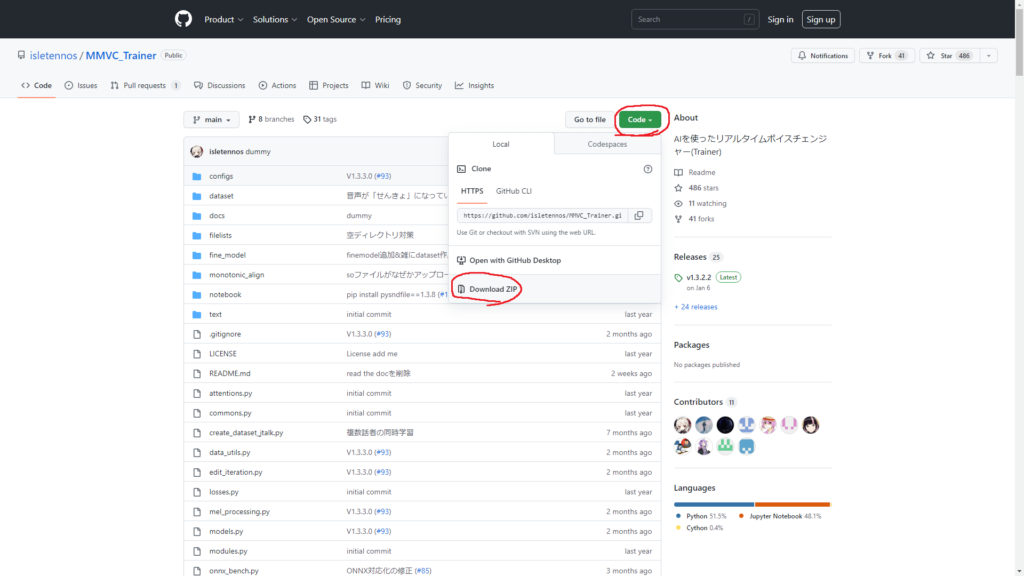
1.MMVC_Trainer v1.3.2.2のダウンロード
MMVC_Trainerのサイトへ移動していただき、緑色の「Code]から「Download ZIP]を選択
適当なところに保存したら展開してください。
2.MMVC公式配布の音声データのダウンロード
さきほどのサイトの下のほうから「”キャラ名”音声データ」をダウンロードしましょう。
今回は「ずんだもん」、「四国めたん」、「春日部つむぎ」の3人になろうと思います。
「九州そら」を追加したかったり、先ほどのキャラが不要な人はそれぞれ工程を追加したり無視してください。
基本的に同じように進めれば導入は問題なくできます。
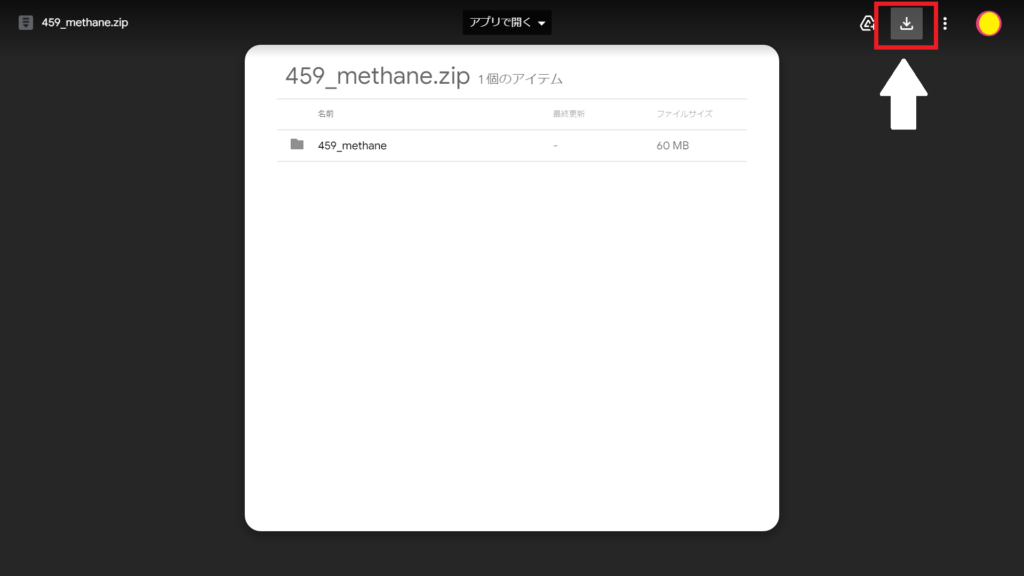
1.「”キャラ名”音声データ」をクリックしてください。

2.Googleドライブに移動するので右上の「ダウンロードボタン」をクリックしてください。
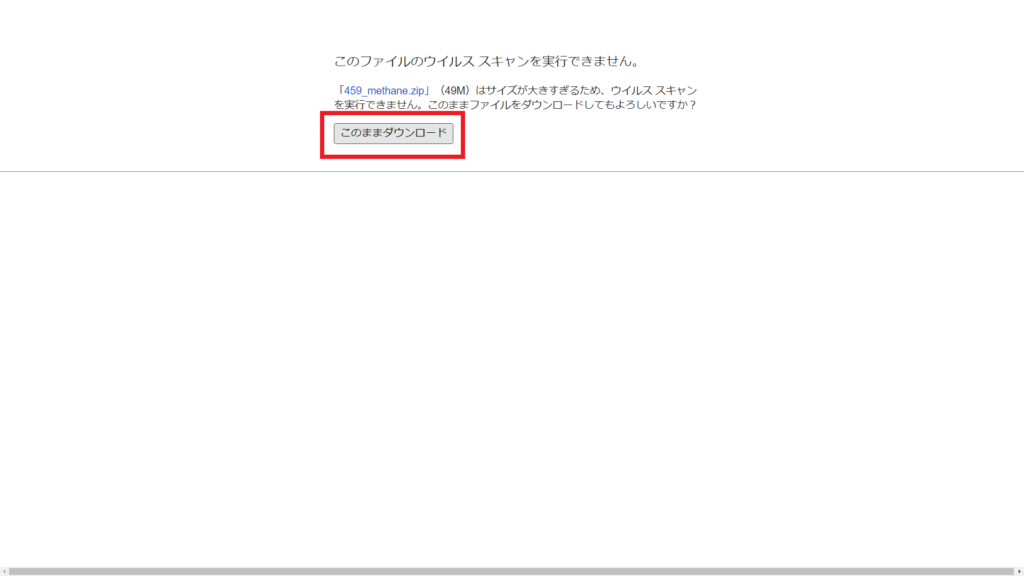
3.「このファイルのウィルススキャンができません。」と表示されますがファイルの容量が大きいためスキャンができません。
「このままダウンロード」をクリックしてダウンロードしてください。
4.なりたいキャラの音声データをすべてダウンロードしてください。
5.ダウンロードしたzipファイルをすべて展開してください。
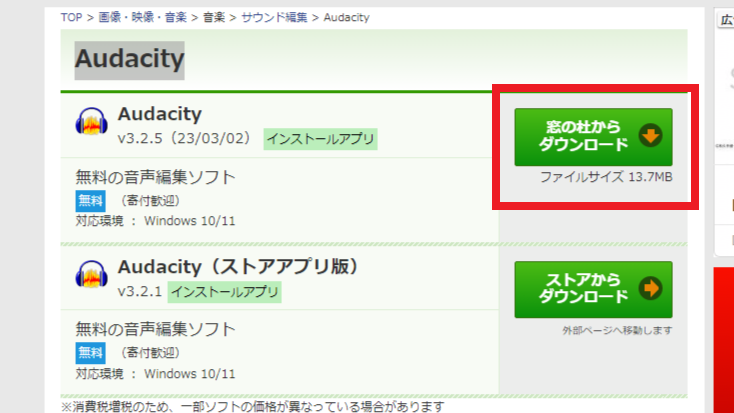
3.機械学習をするために必要なものをダウンロードしましょう
1.Audacityを窓の社からダウンロードしてください。
2.ダウンロードした「audacity-win-3.2.5-x64 .exe」ファイルをダブルクリックしてアプリケーションを実行してください。
3.「Audacityセットアップウィザードの開始」していただき、表示にそって「次へ(N)」を押し続け完了してください。
4.録音するための文の「MMVC向けITAコーパス文章ファイル_配布用.zip」をダウンロードしてください。ここでは「ITAコーパス」という文をダウンロードします。そして、すべて展開してください。
「2.MMVC公式配布の音声データのダウンロード」と同じようにGoogleドライブに移動するのでダウンロードしてください。
5.「ITA_emotion_all.txt」が今回読み上げる文章です。「ITA_emotion_all_hira.txt」はすべてひらがなで読み仮名として利用できます。
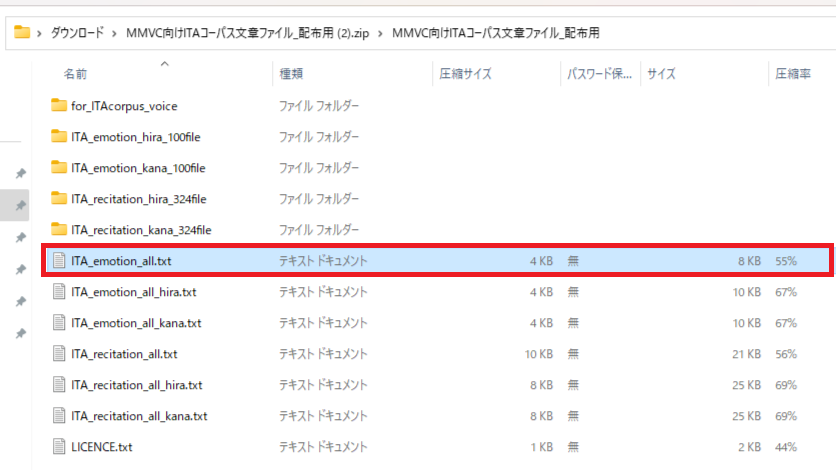
6.「ITA_emotion_all.txt」を開くと画像のように文章が100個あります。これを一個ずつ録音していただきます。
4.Audacityの設定
1.Audacityを開いて録音するための設定をしましょう。
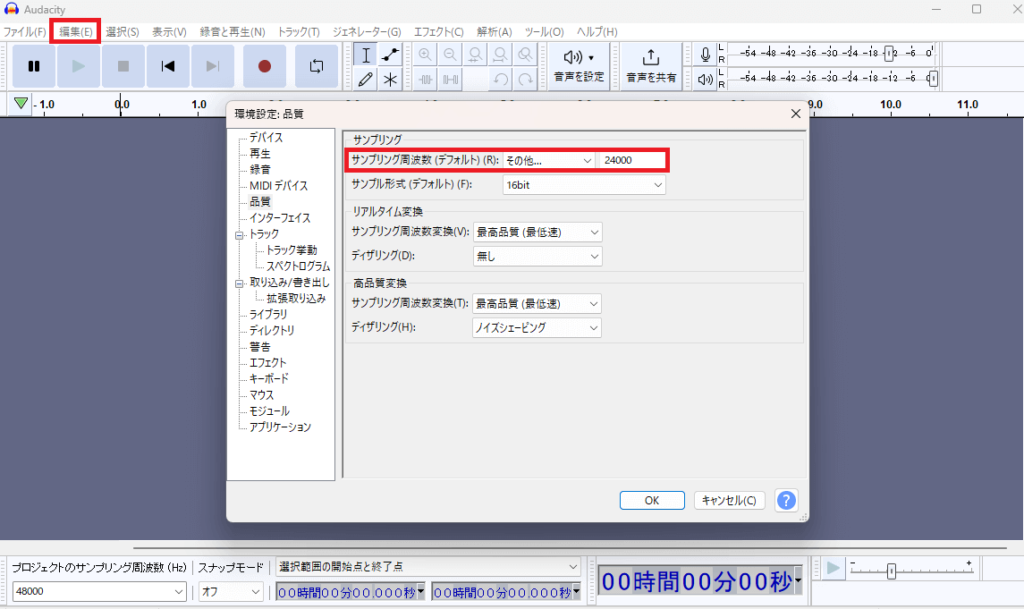
2.左上の「編集」から「環境設定」を押して、「サンプリング周波数」を「その他」「24000」と入力して「OK」を押してください。
3.上の「音声設定」から「音声環境設定」から「チャンネル」を「モノラル」に変更して「OK」を押してください。
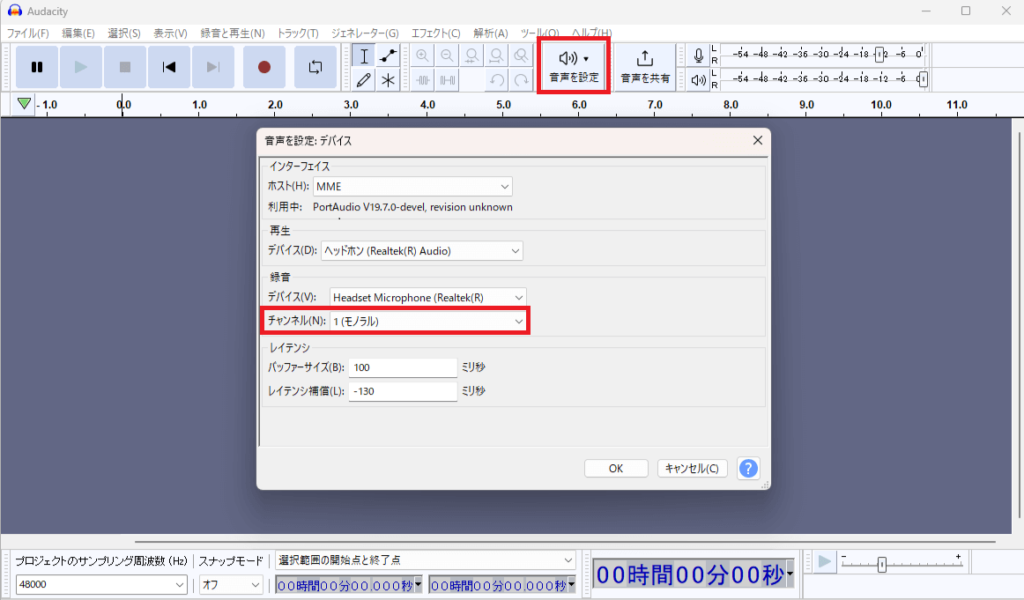
4.各種設定をしたら一度Audacityを終了して開きなおしてください。
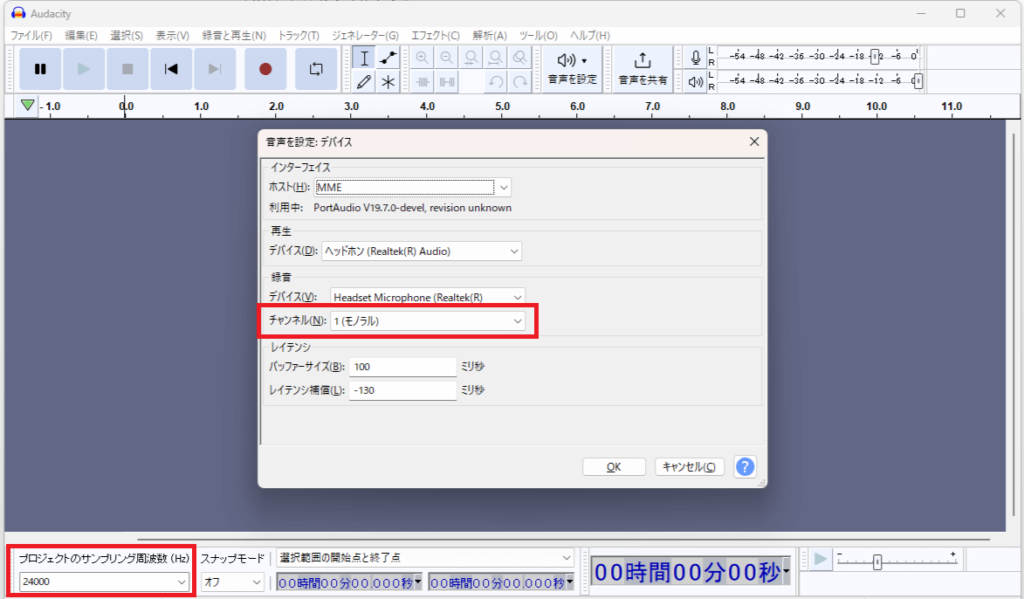
5.Audacityを開き変更した箇所がちゃんと変わってるか確認してください。
5.Audacityで録音開始
1.「ITAコーパス(ITA_emotion_all.txt)」「ITAコーパスひら(ITA_emotion_all_hira.txt)」と「Audacity」を開いてください。
「ITAコーパスひら(ITA_emotion_all_hira.txt)」で漢字の読み仮名を確認しながら録音してください。読み仮名が違うと学習がうまくいきません。
配置例
2.上の録音ボタンを押して録音開始してください。
※ここでも、「モノラル」「24000Hz]となっているのを確認してください。
普段喋るときと同じように読み上げると学習の精度が上がります。
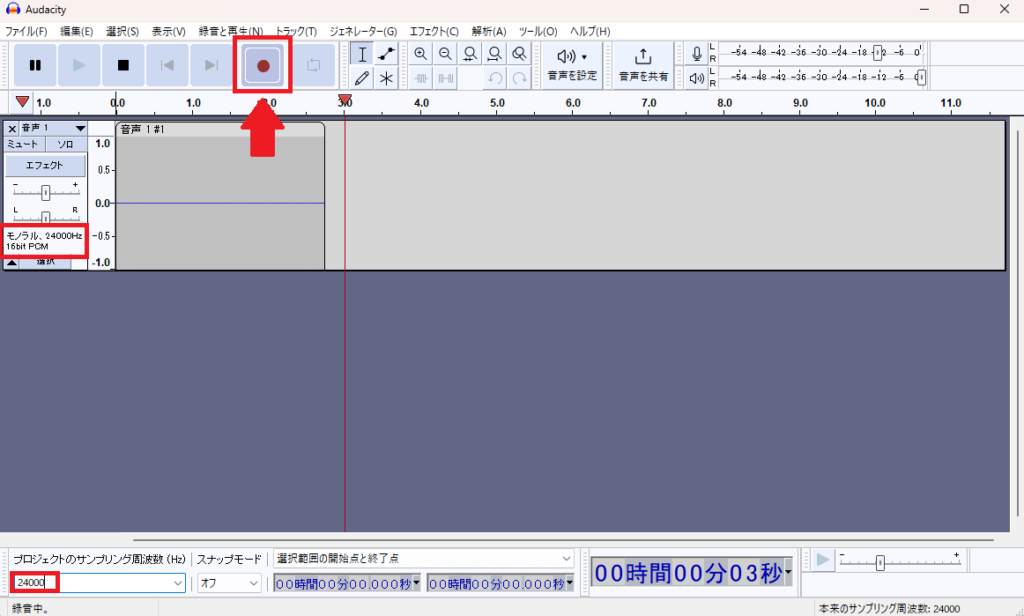
3.1番の「え、噓でしょ」と言ったら停止ボタンを押してください。無音の場所は少ないほうがいいです。
録音する音声は絶対に「1秒以上、16秒未満」にしてください。機械学習がこの秒数でないとできないからです。
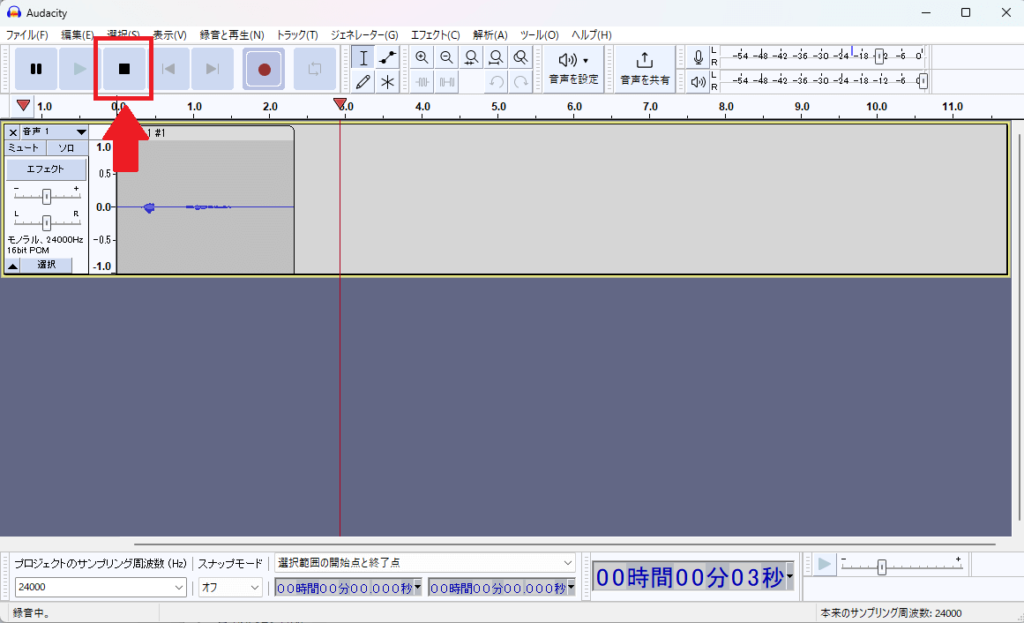
4.録音した音声を聞いて、噛んだり詰まったりせず普通に読めていれば大丈夫です。
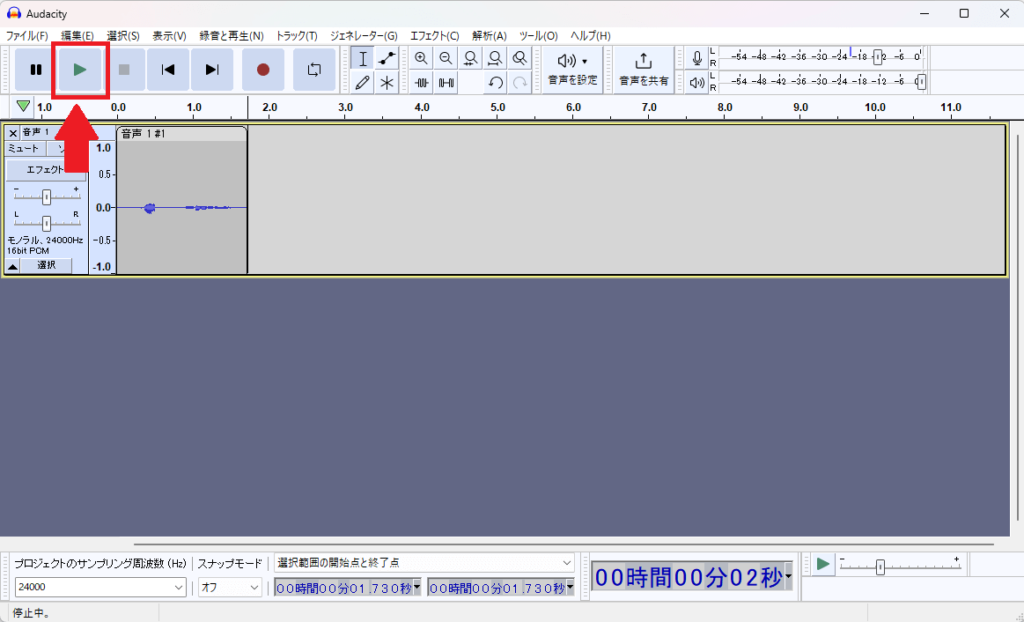
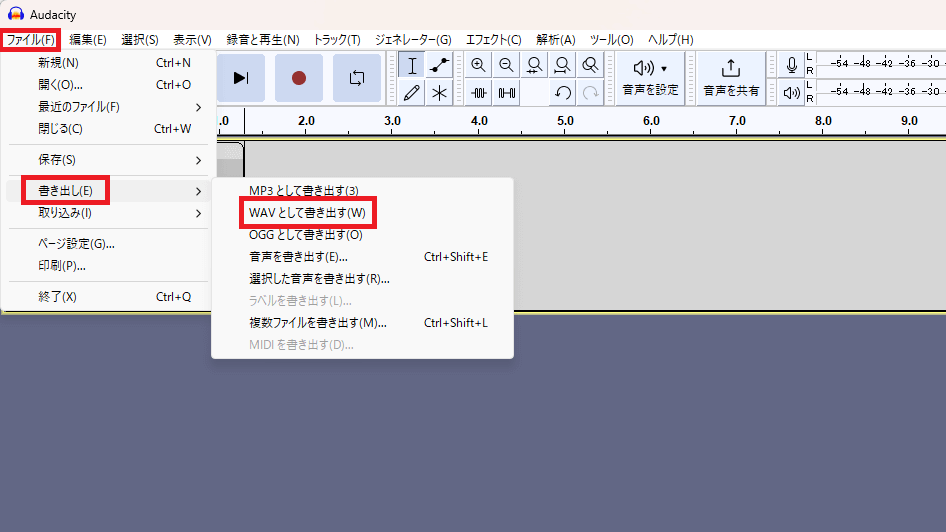
5.録音が完了したら、「ファイル(F)」→「書き出し(E)」→「WAVとして書き出す(W)」を押してください。
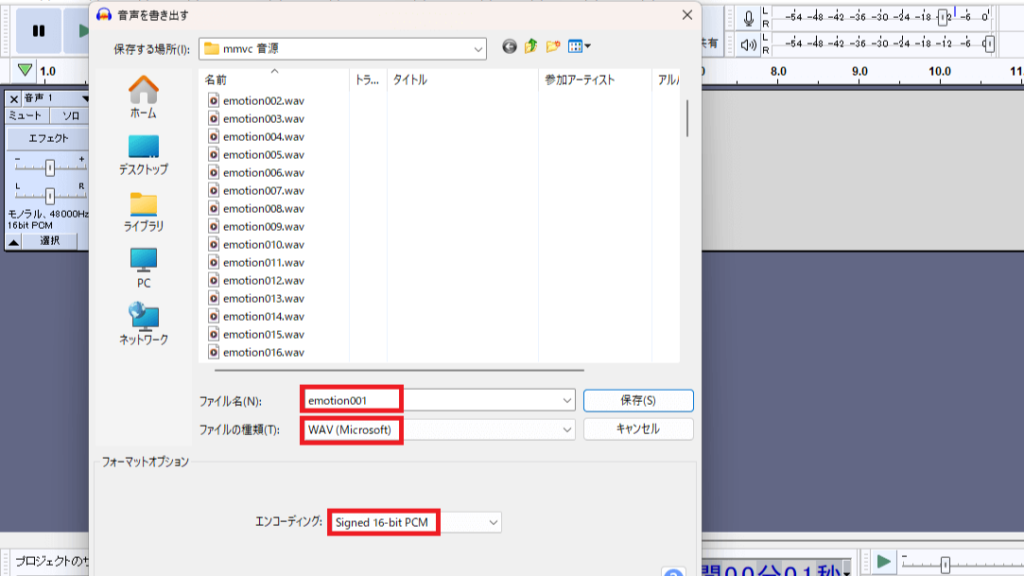
6.ファイル名を「emotion001」と入力してください。数字は3桁で必ず入力してください。
20行目の文章を読んでいる場合は「emotion020」と入力してください。
必ず読んでいる文章と数字が一致するように定期的に確認してください。
ファイル種類が「MAV(Microsoft)」となって、エンコーディングが「Signed 16-bit PCM」となっているかを確認してください。
7.今までの「5-2から5-6」までの作業を100回おこなってください。
6.MMVC_Trainerに「target データフォルダ」を作成
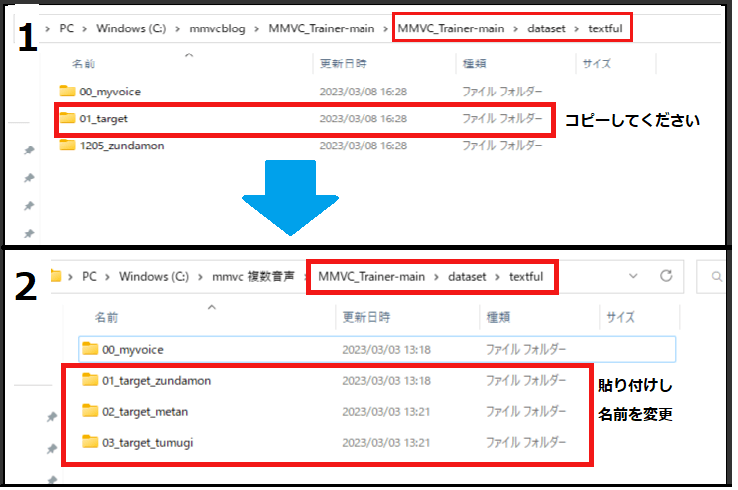
最初にダウンロードし展開した「MMVC_Trainer-main」のフォルダを開いて「dataset」→「textfu」にある「01_target」のコピーを2つ作成して「01_targe」と「01_targetコピー」のファイルの名前を画像と同じようにしてください。
「1205_zundamon」は消去してください。
「ずんだもん」「四国めたん」「春日部つむぎ」の3人になる場合は赤く囲われている場所は画像と同じ状態にしてください。
| [target データフォルダ名] コピー用 |
| 01_target_zundamon |
| 02_target_metan |
| 03_target_tumugi |
7.「multi_speaker_correspondence.txt」の書き換え
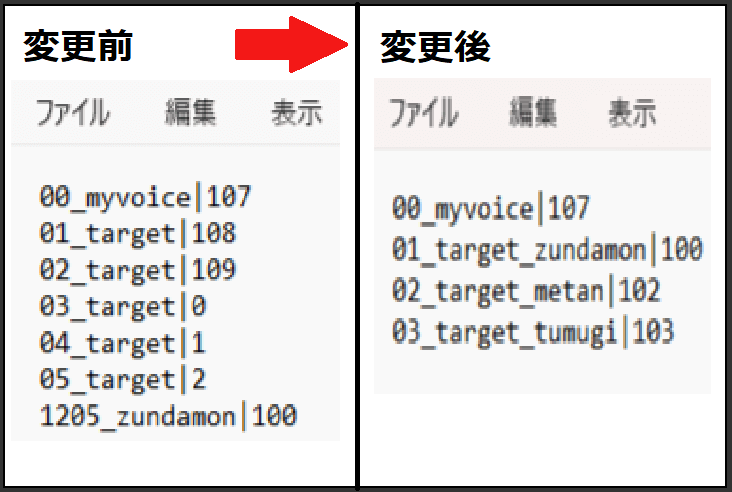
1.「MMVC_Trainer-main」を開き「dataset」を開いてください。そして、「multi_speaker_correspondence.txt」を開いてください。
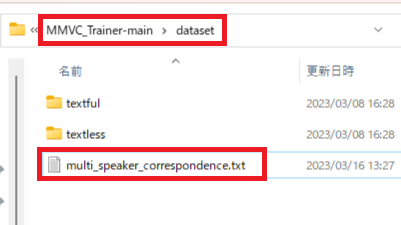
2.「multi_speaker_correspondence.txt」をメモ帳などで開き書き換えてください。
「textfuフォルダ名」と「キャラ番号」に書き換えます。
「ずんだもん」は「100」
「九州そら」は「101」
「四国めたん」は「102」
「春日部つむぎ」は「103」
「ずんだもん」「四国めたん」「春日部つむぎ」の3人になる場合は画像と同じ状態にしてください。
| [target データフォルダ名] コピー用 |
| 01_target_zundamon|100 |
| 02_target_metan|102 |
| 03_target_tumugi|103 |
8.「”キャラ名”音声データ」をMMVC_Trainerに配置
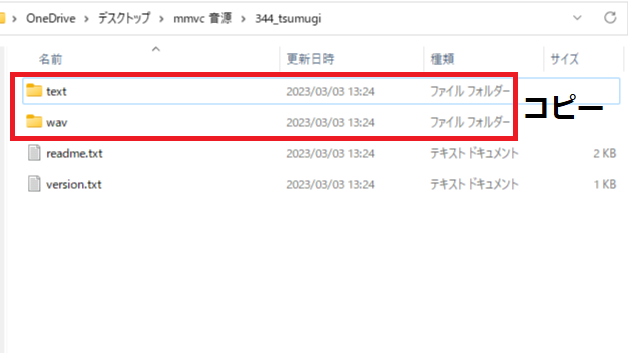
1.「2.MMVC公式配布の音声データのダウンロード」でダウンロードし展開した「344_tumugi」ファイルを開いて「text」と「wav」をコピーしてください。
※他のキャラはそのキャラの音声データファイルを開いてコピーしてください。
今回は「春日部つむぎ」で説明します
2.「6.MMVC_Trainerに「target データフォルダ」を作成」で作成した「03_target_tumugi」を開いて貼り付けしてください。
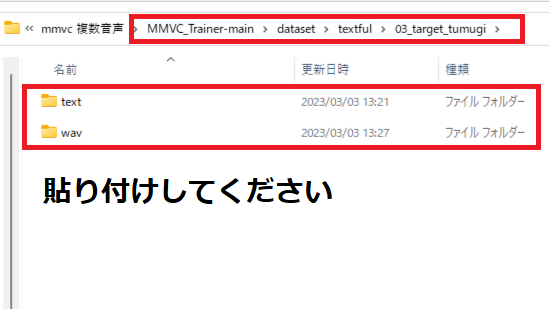
3.「8-1から8-2」の作業を自分がなりたいキャラのぶん配置してください。
9.「自分の音声データ」と「テキストファイル」をMMVC_Trainerに配置
1.3-4でダウンロードした「MMVC向けITAコーパス文章ファイル_配布用.zip」を開き、「ITA_emotion_hira_100file」を開いてください。
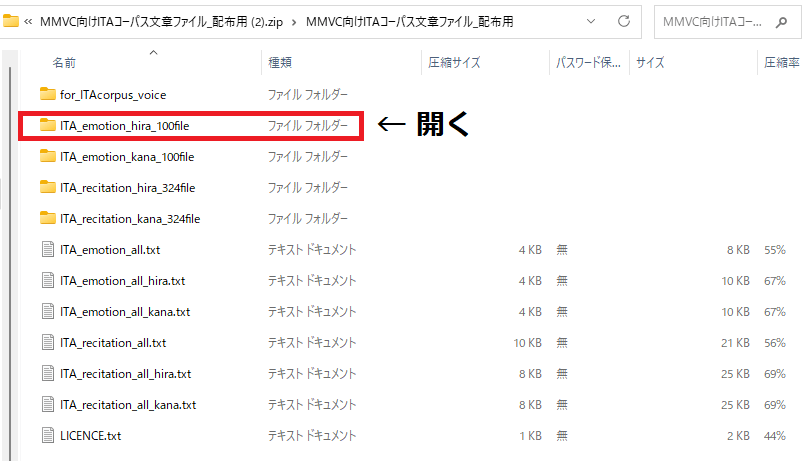
2.「ITA_emotion_hira_100file」の中にある「emotion001.txt」~「emotion100.txt」をコピーしてください。
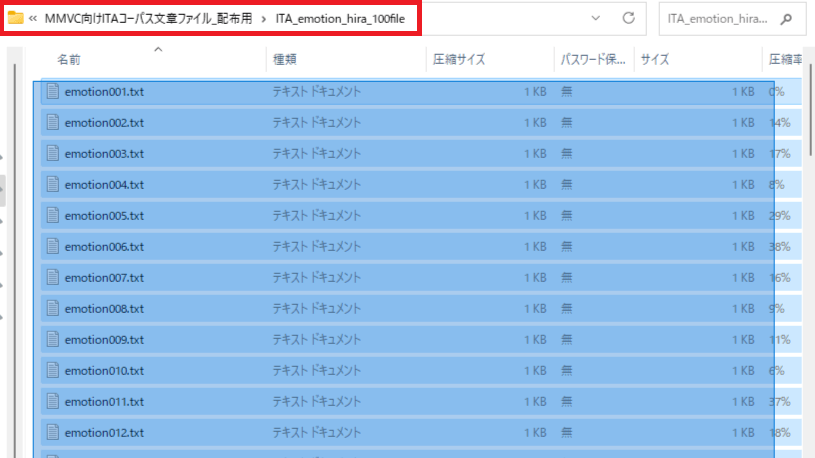
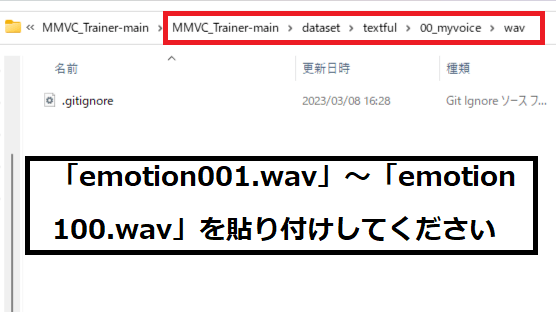
3.「6.MMVC_Trainerに「target データフォルダ」を作成」で開いた「MMVC_Trainer-main」のフォルダを開いて「dataset」→「textfu」にある「00_myvoice」を開き「text」ファイルに貼り付けしてください。
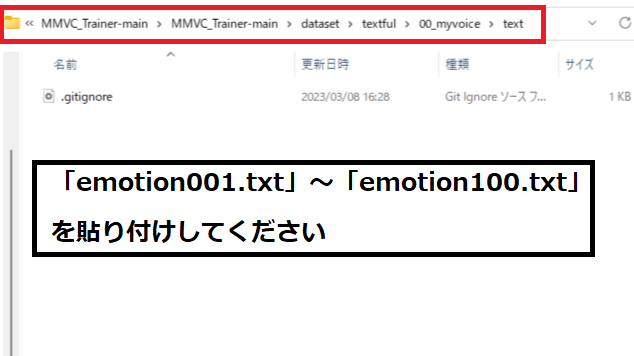
4.先ほどの「00_myvoice」に戻っていただき「5.Audacityで録音開始」で録音した「emotion001.wav」~「emotion100.wav」をコピーしてください。

5.「8-3」の「MMVC_Trainer-main」のフォルダを開いて「dataset」→「textfu」にある「00_myvoice」を開き「text」ファイルに貼り付けしてください。
10.事前学習済みデータのダウンロード
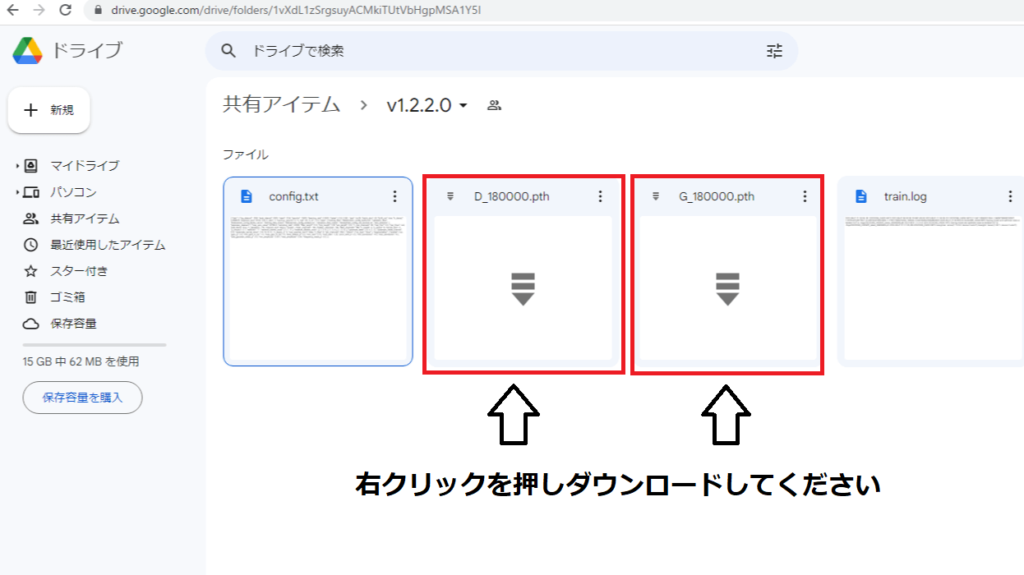
事前学習済みデータの「G_180000.pth」「D_180000.pth」を右クリックを押しダウンロードしてください
11.事前学習済みデータの配置
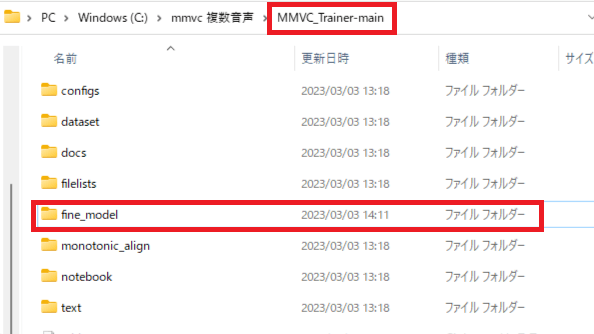
「MMVC_Trainer-main」を開き「9.事前学習済みデータのダウンロード」でダウンロードした「G_180000.pth」「D_180000.pth」を「fine_model」に貼り付けしてください。
12.「Googleドライブ」に「MMVC_Trainer-main」をアップロード
Googleを開き右上の「画像」と「自分のグーグルカウント」の間の9つ点があるボタンをクリックし「Googleドライブ」を開いてください。

2.「MMVC_Trainer-main」を「Googleドライブ」にドラック&ドロップしてください。
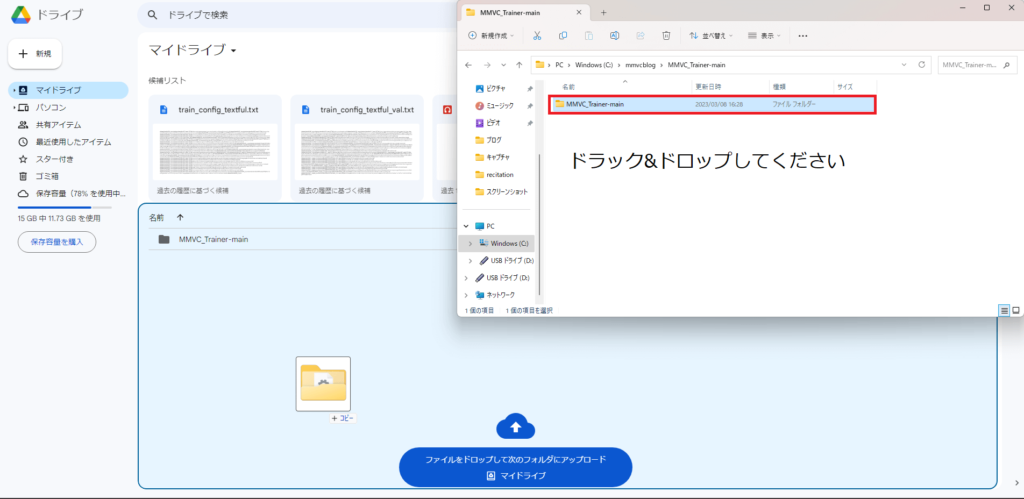
「MMVC_Trainer-main」ファイルが二重になっていないことを確認しアップロードしてください
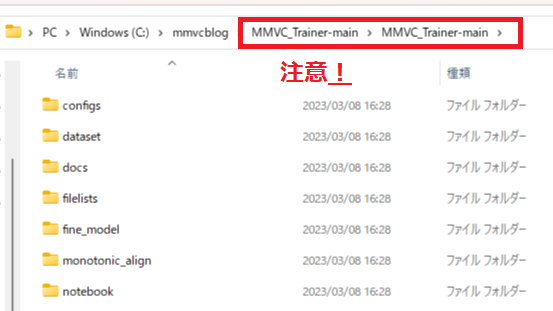
13.「Googleドライブ」でアプリをダウンロード
1.「MMVC_Trainer-main」を右クリックし、「アプリで開く」→「アプリを追加」を押してください。
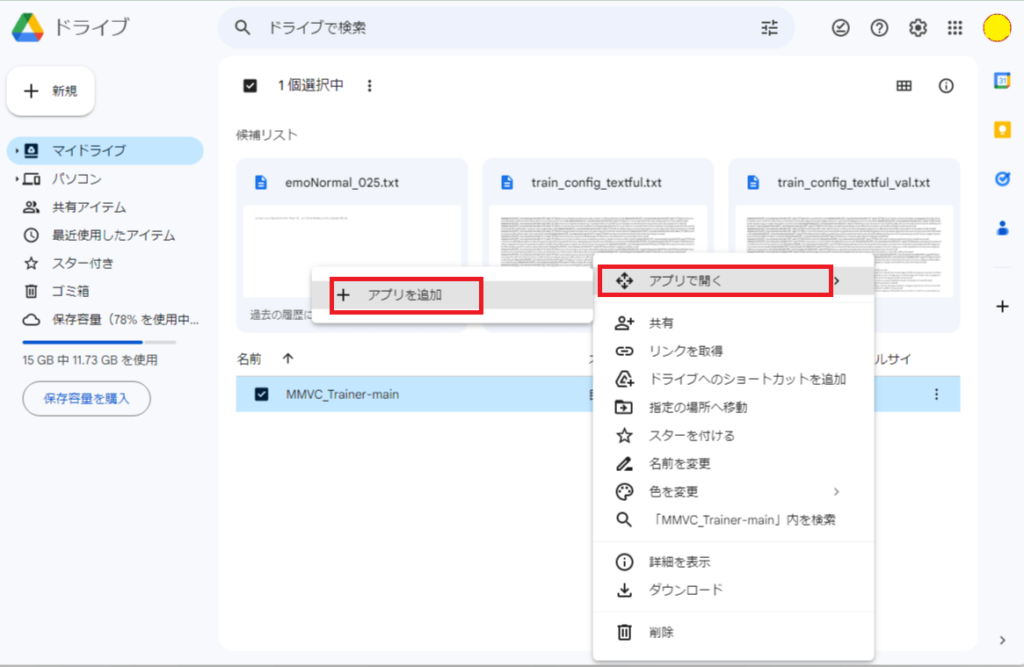
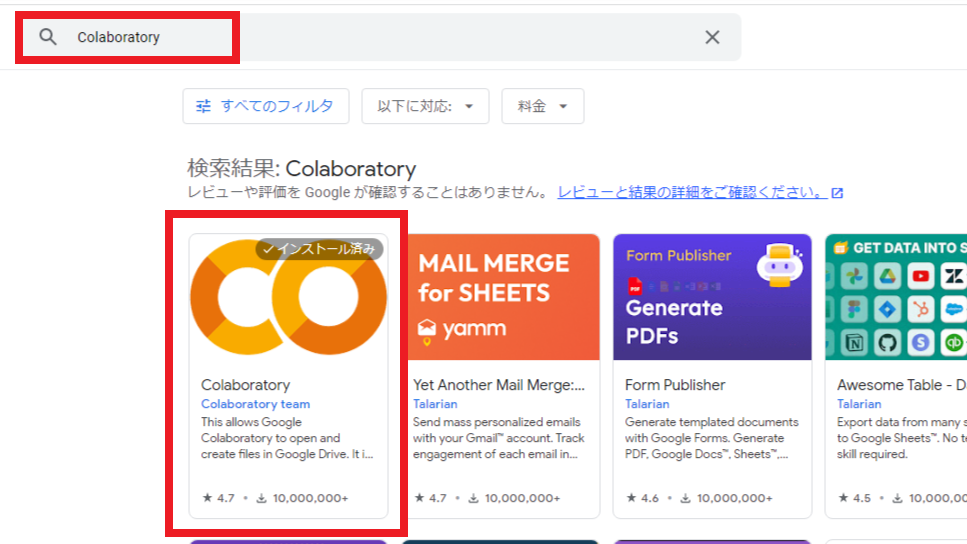
2.上の検索欄から「Colaboratory」と入力してインストールしてください。
14.「Googleドライブ」から「MMVC_Trainer-main」を開き「01_Create_Configfile.ipynb」の実行
1.「Googleドライブ」から「MMVC_Trainer-main」→「notebook」→「01_Create_Configfile.ipynb」を開いてください。
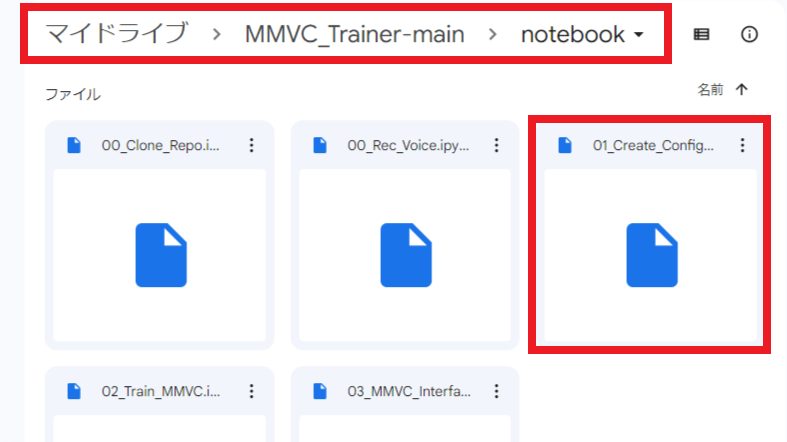
2.このように「12.「Googleドライブ」でアプリをダウンロード」でダウンロードしたアプリで起動できていたら画像のようになります。
開けない場合はインストールがちゃんとできているか再確認してください
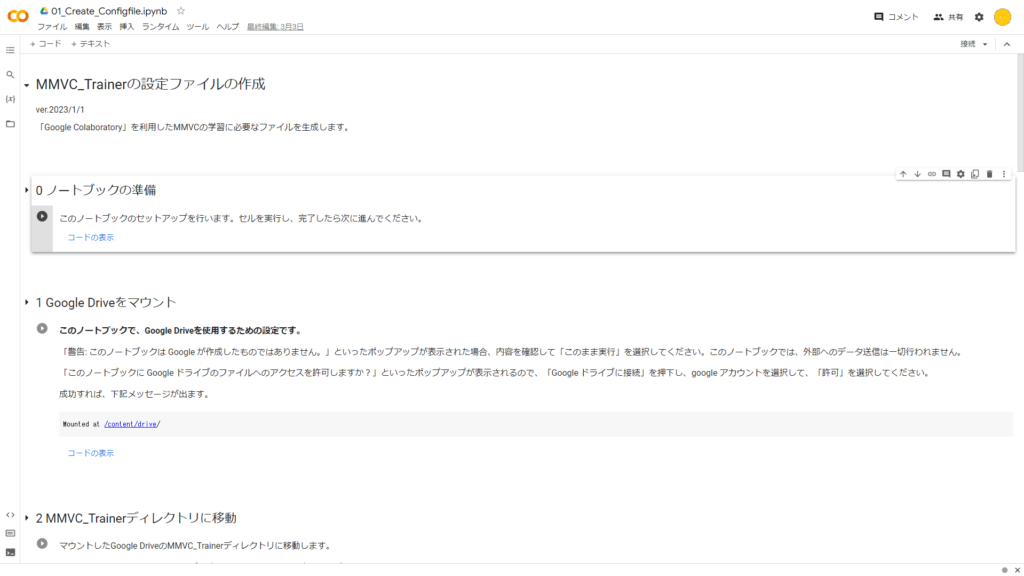
3.「0ノートブックの準備」の再生ボタンのようなボタンを押して実行してください。
押したらセットアップが開始されるので完了したら横に緑色のチェックマークがつくのでついたら完了です。
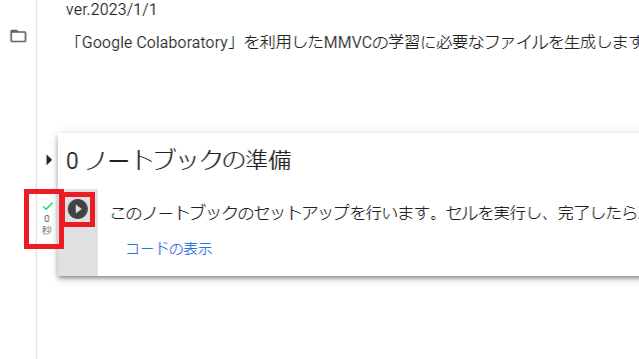
4.「1 Google Driveをマウント」を実行してください。
「このノートブックに Google ドライブのファイルへのアクセスを許可しますか?」と表示されるので、「Google ドライブに接続」を押し、google アカウントを選択して、「許可」を選択してください。
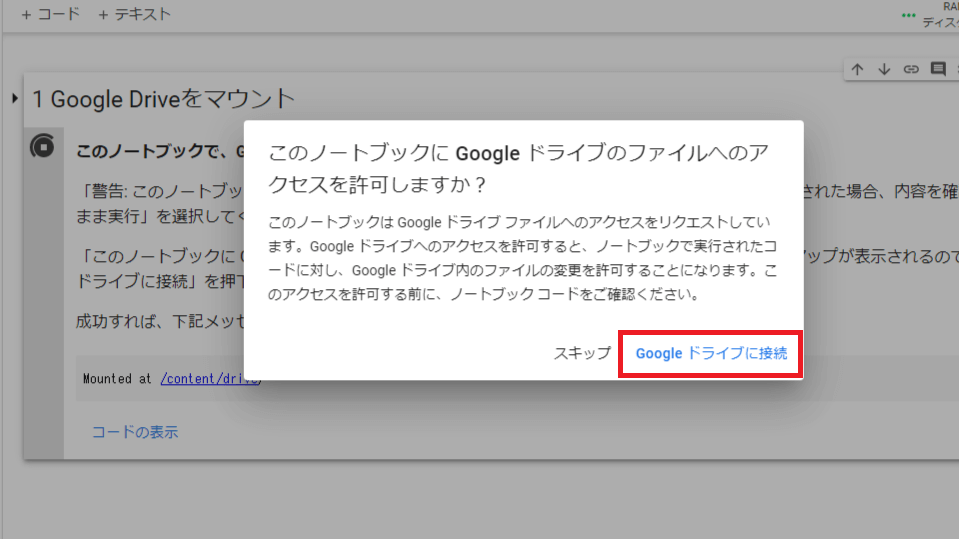
完了したら「mounted at /content/drive」と表示されます
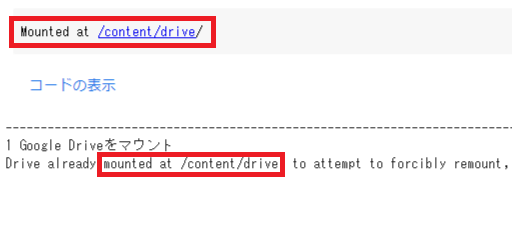
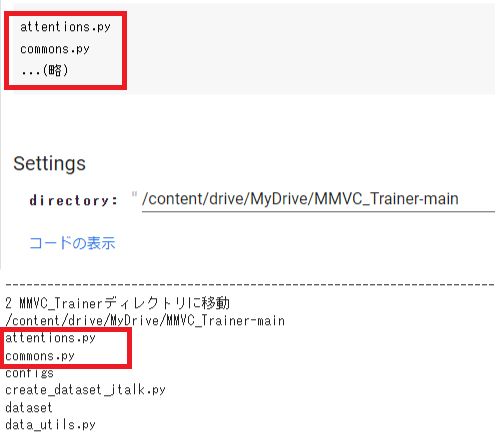
5.「2 MMVC_Trainerディレクトリに移動」を実行してください。
「Settings」[directory: /content/drive/MyDrive/MMVC_Trainer-main]はそのままで大丈夫です。

完了したら「attentions.py commons.py」と表示されます
6.「3 ライブラリのインストール」を実行してください。
数分かかる場合があるのでのんびり待ちましょう
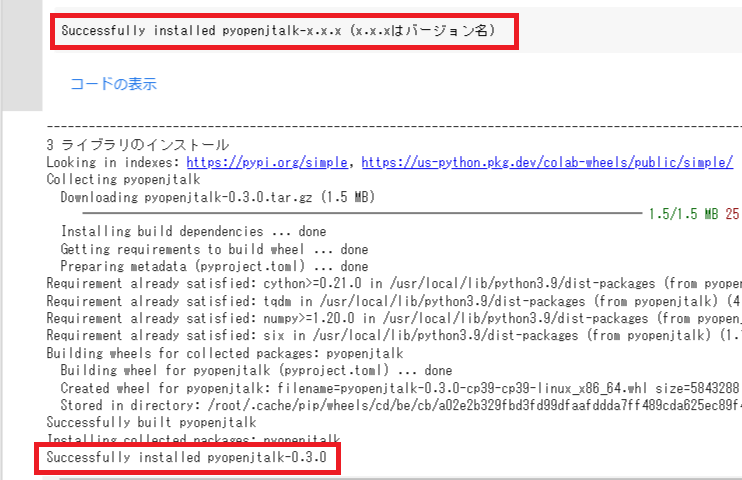
完了したら「Successfully installed pyopenjtalk-x.x.x (x.x.xはバージョン名)」と表示されます
7.「4 config系Fileを作成する」を実行してください。
「-m:複数話者の学習を同時に行いたい場合に使用します。」にチェックをいれて、「4 config系Fileを作成する」を実行してください。
実行ボタンの次にチェックがついたら次に行ってっください

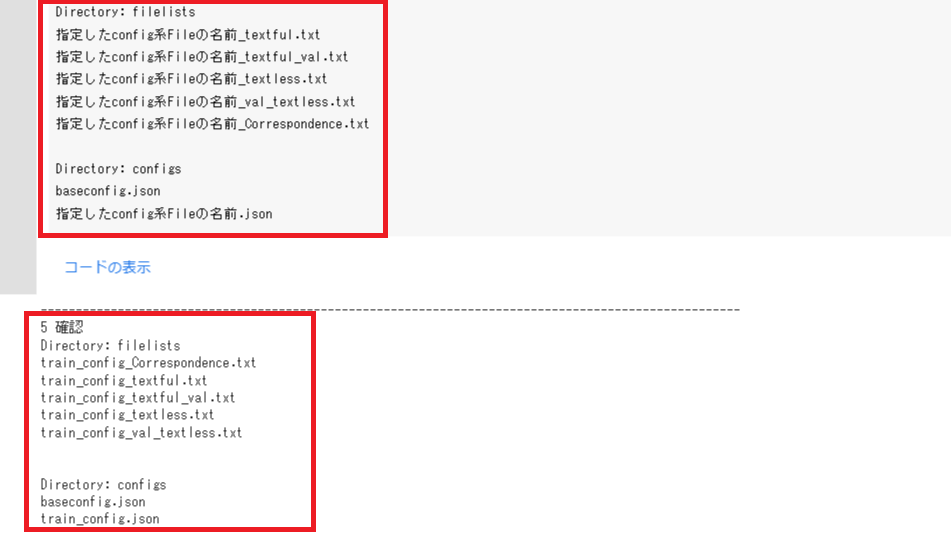
8.「5 確認」の実行
「5 確認」を実行してください。
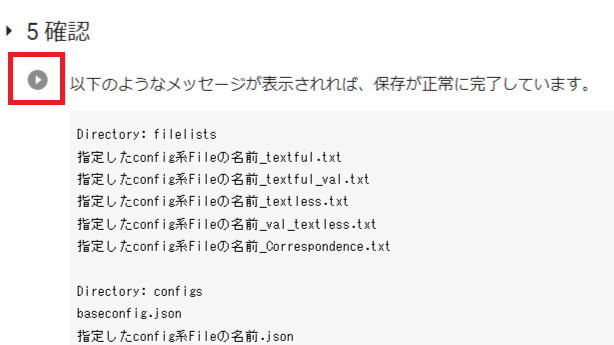
完了したら
「Directory: filelists
指定したconfig系Fileの名前_textful.txt
指定したconfig系Fileの名前_textful_val.txt
指定したconfig系Fileの名前_textless.txt
指定したconfig系Fileの名前_val_textless.txt
指定したconfig系Fileの名前_Correspondence.txt
Directory: configs
baseconfig.json
指定したconfig系Fileの名前.json」
と表示されます
15.「Googleドライブ」から「MMVC_Trainer-main」を開き「02_Train_MMVC.ipynb」の実行
1.「0ノートブックの準備」を実行してください。
押したらセットアップが開始されるので完了したらチェックマークがつくのでついたら完了です。
2.「14-4」と同じように「1 Google Driveをマウント」を実行してください。
「このノートブックに Google ドライブのファイルへのアクセスを許可しますか?」と表示されるので、「Google ドライブに接続」を押し、google アカウントを選択して、「許可」を選択してください。
完了したら「mounted at /content/drive」と表示されます
3.2 MMVC_Trainerディレクトリに移動を実行
5.「14-5」と同じように「2 MMVC_Trainerディレクトリに移動」を実行してください。
「Settings」[directory: /content/drive/MyDrive/MMVC_Trainer-main]はそのままで大丈夫です。
完了したら「attentions.py commons.py」と表示されます
6.「3 GPUの確認」を実行してください。
チェックマークがついたら完了です。

7.「4 ライブラリのインストール」を実行してください
10分ほどかかる場合があるのでのんびり待ちましょう

8.「5 tensorboardの起動」を実行してください
チェックマークがついたら完了です。

9.「6 学習を実行する」を実行してください
「New_or_Resume:」は「New」となっているのを確認してください。
再度学習する場合は「New_or_Resume:」は「Resume」を選んでください

10.学習が終わるまで放置してください
ブラウザを消さなければ学習は進むのでブラウザはそのまま別のことなどして放置してください。
約6時間ほど経過すると強制的に学習が終了します。
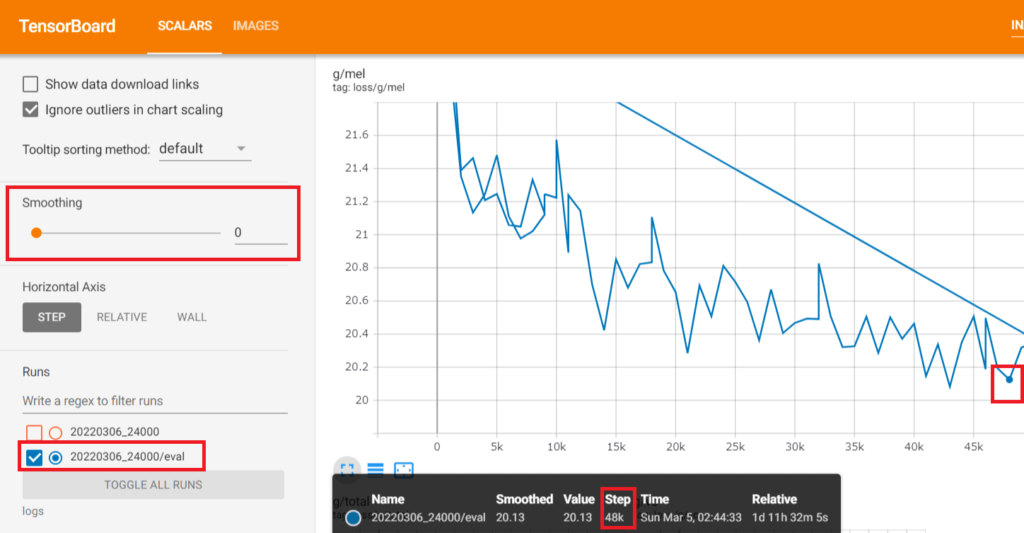
「g/mel」という数値が最低でも19台になるまでは学習をすすめてください。それよりも低くなればなるほど音声の変換精度が高いということです
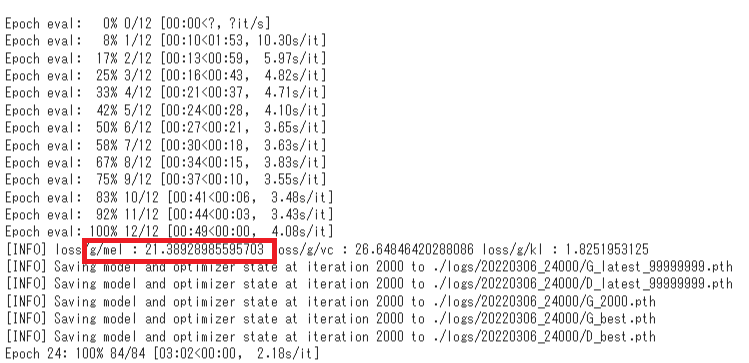
11.学習終了後「g/mel」の低いデータを確認する
学習が終了したらこのように強制的に学習ができなくなるので、「15-8」「「5 tensorboardの起動」を実行してください」で開いたtensorboardで「g/mel」の低いデータを確認してください。
一日ほど経つとまた学習ができるようになります

このようにデータが表示されてない場合は「更新」ボタンを押して「logs」を開いてください。
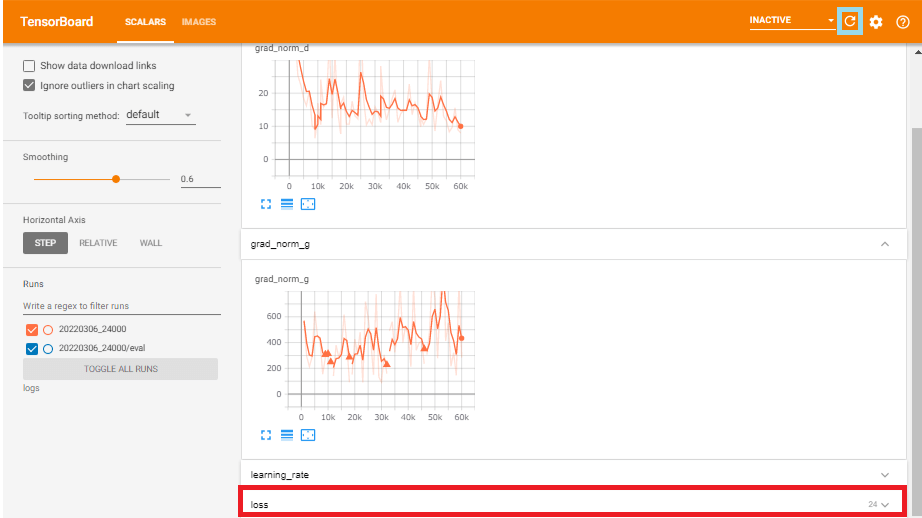
「Smoothing」を「0」にして、「Runs」は「青」の方だけチェックを入れて、「偶数のstep」の一番低い数値の物を確認しておいてください。
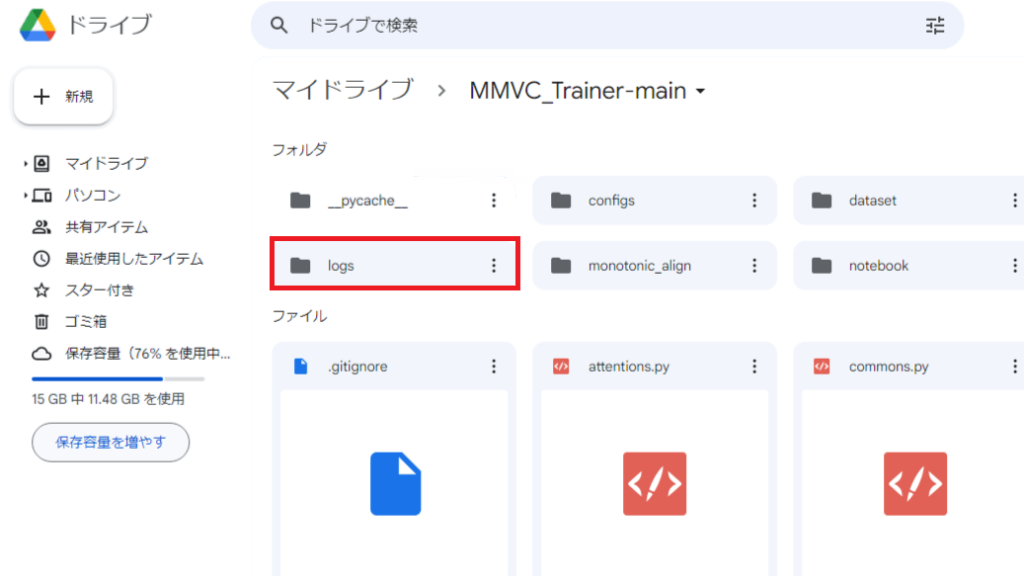
12.「logs」というファイルが追加されているので開いてください。
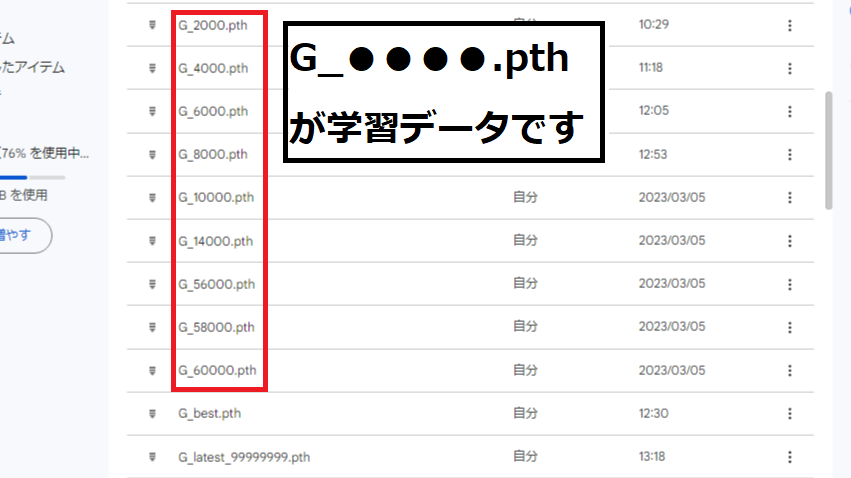
13.「logs」→「20220306_24000」→「g/melの低かった偶数のstep」と「g/melの高かった偶数のstep」を2つほど残してそれ以外の「G_〇〇〇〇.pth」は消去してください。
14.納得いく学習成果がでるまで「15.「Googleドライブ」から「MMVC_Trainer-main」を開き「02_Train_MMVC.ipynb」の実行」の工程を繰り返してください。
16.「MMVC_Client」のダウンロードし展開
AIを使ったリアルタイムボイスチェンジャー「MMVC」の本体です。
MMVC_Trainerで学習したモデルを使ってリアルタイムでVCを行います。
ダウンロードが完了したら「Windows(C:)」の中に新規フォルダ作成「mmvc_multi」という名前で作りその中に展開してください
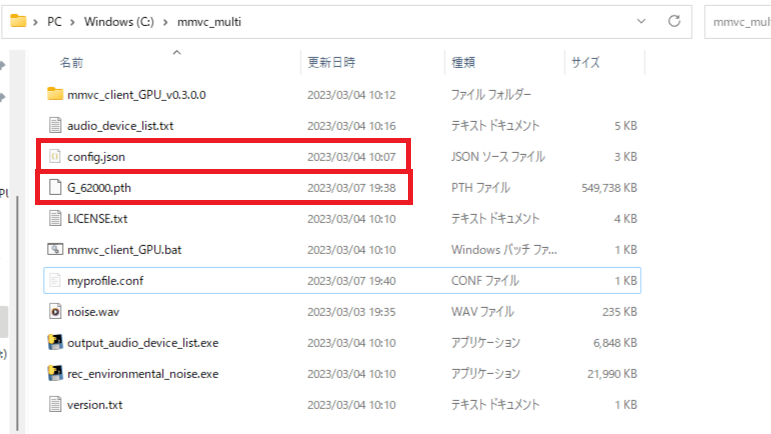
※黒く線が引いてあるとこはまだ関係ないので赤く囲んだ箇所と9個の項目があれば大丈夫です。
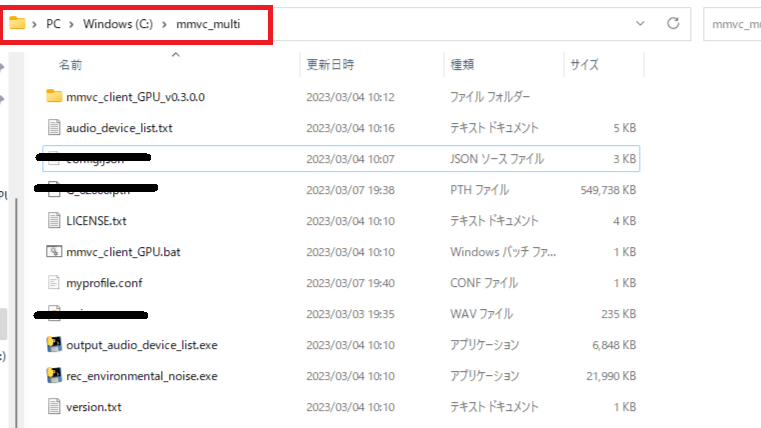
17.「MMVC_Client」を開き「output_audio_device_list.exe」を開く
1.「MMVC_Client」を開き「output_audio_device_list.exe」を開いてください。
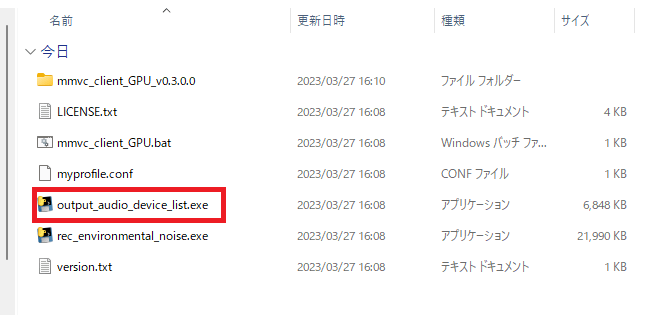
2.「windowsによってPCが保護されました」と出ますので「詳細情報」を押し「実行」をおしてください。
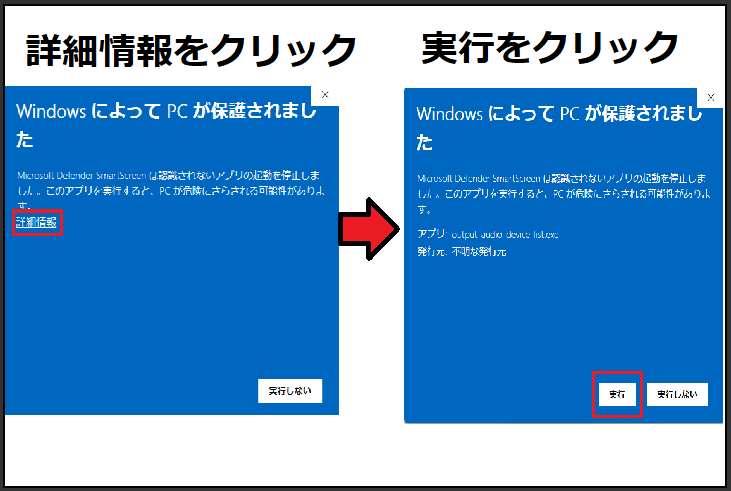
3.黒いウィンドウが一瞬でたら完了です。
4.「audio_device_list.txt」というファイルが追加されていれば完了です。
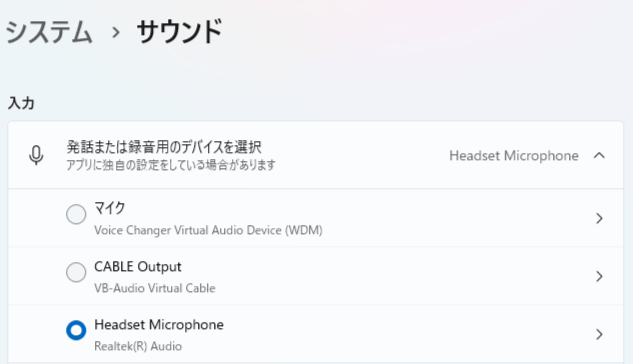
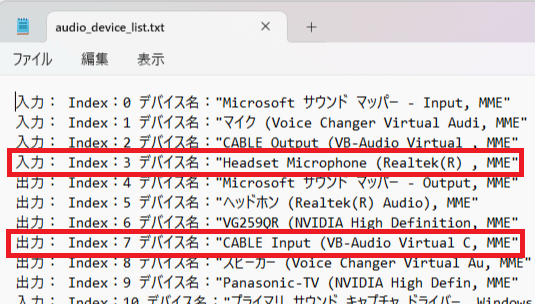
18.「audio_device_list.txt」をデバイス名の確認
使っているデバイスで名前が変わってくるので自分が普段使っているデバイス名が表示されているのが確認できたら大丈夫です。
私の環境ではこうなります
入力デバイス 「Headset Microphone(Realtek(R)」
出力デバイス 「CABLE Input (VB-Audio Virtual C」
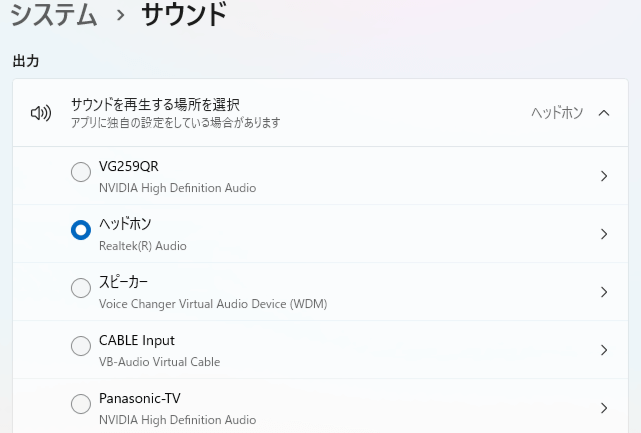
「audio_device_list.txt」内でのデバイス名はこうなります
ディスコードや配信などでボイスチェンジャーを使う場合は、コンピュータ上でアプリのオーディオ出力を別のアプリの入力に渡す事が出来る「仮想オーディオ・ケーブル (Virtual Audio Cable)」をダウンロードしてください。
簡単に解説するので必要な人は手順にそってダウンロードしてください。
1.「Windowsマーク」ダウンロードボタンをクリックしてください。
2.zipファイルを展開して開いていただき下の方にスクロールして「VBCABLE_Setup_x64.exe」を右クリックして「管理者として実行」してください。
3.画像のようなタブが現れるので「Install Driver」をクリックしてください。

4.インストールが完了したら画像のような表示がでます。
「インストールは無事に終了しました。インストールを完全に終えるには再起動してください。」と書いてあります
5.このようなブラウザーが表示されますが消してしまって大丈夫です

7.再起動したら「システム」から「サウンド」に「CABLE Input」があれば完了です。
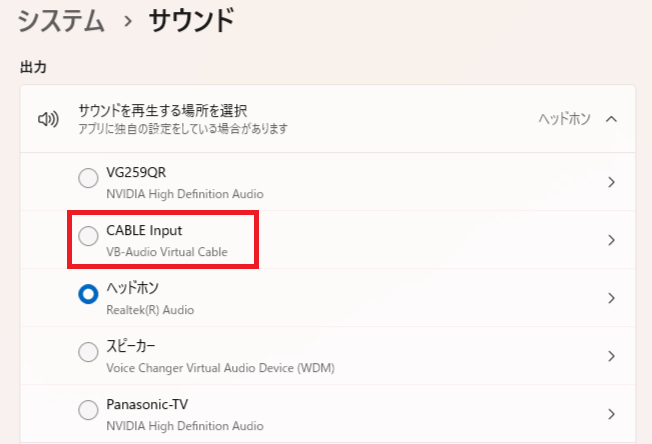
19.「MMVC_Client」から「myprofile.conf」の書き換え
1.「myprofile.conf」を開いてください
2.入力デバイスと出力デバイスの設定
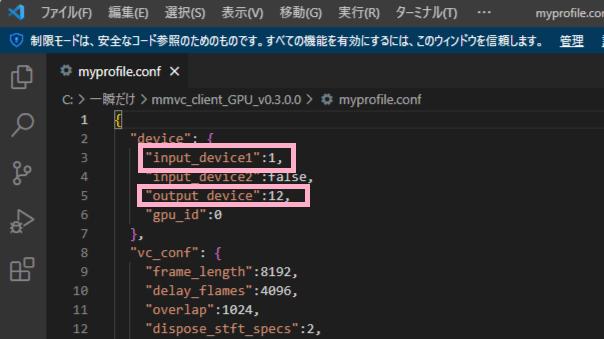
「”input_device1″」は入力デバイス(マイク)は先ほど確認したものをコピーして貼り付けてください。私の場合は「Headset Microphone(Realtek(R)」となります。
「”output_device”」は出力デバイス「CABLE Input (VB-Audio Virtual C」となります。ここは先ほど紹介したVirtual Audio Cableを使用している方は共通です。
貼り付けは、「 “output_device”:」のように「:」より必ず先に貼り付けてください。
コピーは、「”CABLE Input (VB-Audio Virtual C, MME”」のように「”~~~~”」この「”」を前と後ろにあるようにコピーしてください。
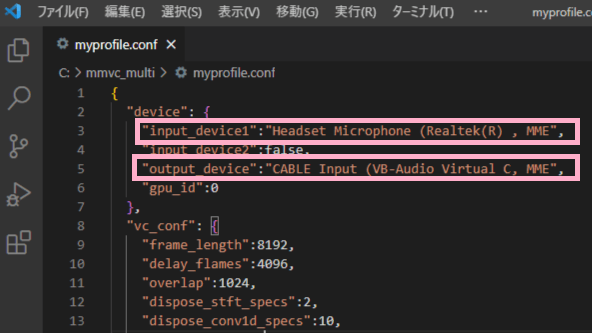
20.「”path”: {」の書き換えの準備
1.「MMVC_Client」のなかにある「rec_environmental_noise.exe」を開いてください。
Windowsに止められたら先ほどの様に「詳細情報」から「実行」してください
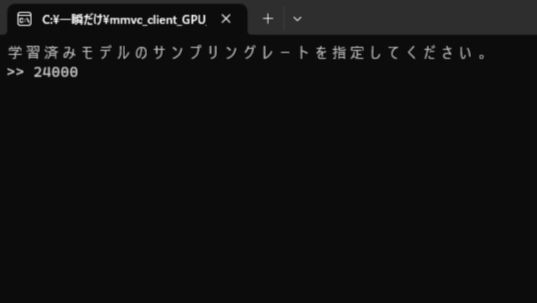
2.黒いウィンドウが表示だれたら「学習済みモデルのサンプリングレートを指定してください。」と表示されたら「24000」と入力して「ENTER」を押してください。
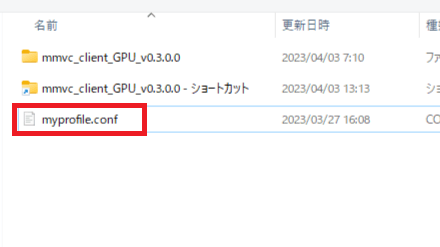
3.フォルダが表示されるので「myprofile.conf」を選んでください
4.「あなたの環境ノイズを録音します。マイクの電源を入れて、何もせずに待機していてください。
5秒後に録音を開始します。5秒間ノイズを録音します。完了するまで待機していてください。」
と表示されるので録音できる状態で何もせず静かにしてください。
録音が完了したら、「完了しました」とでるので消して大丈夫です。

5.「noise.wav」というファイルが追加されます。
6.「Googleドライブ」の「MMVC_Trainer-main」を開き「logs」→「20220306_24000」→「g/melの低かったG_〇〇〇〇.pth」と「config.json」をダウンロードしてください。
「config.json」は上の方にあり「g/melの低かったG_〇〇〇〇.pth」は下の方にスクロールしたらあると思います。画像は一枚にまとめたのでこのようになっています。
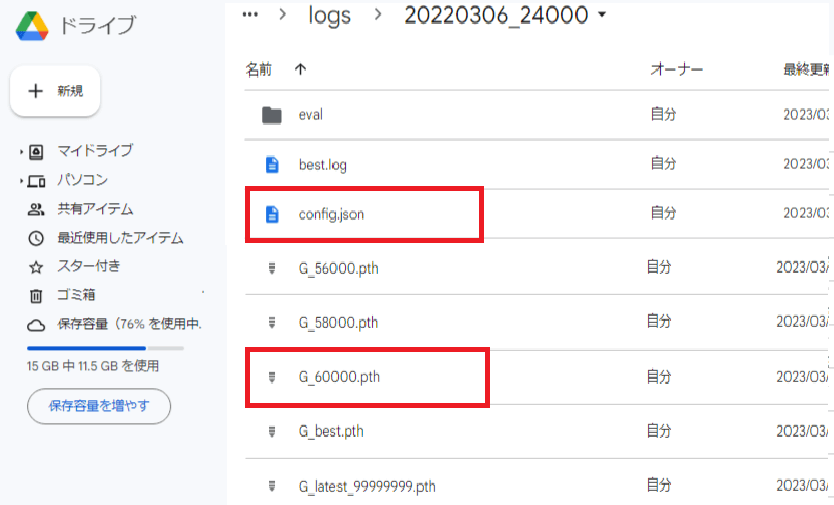
7.「MMVC_Client」にダウンロードした「g/melの低かったG_〇〇〇〇.pth」と「config.json」を貼り付けてください。
21.「”path”: {」の書き換え
1.「myprofile.conf」を開いてください
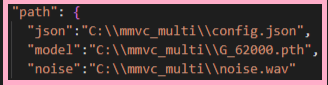
2.「”json”:」は先ほどダウンロードした「config.json」をパスを指定するので、「”json”:”C:\\mmvc_multi\\config.json”」となります。
3.「”model”:」は先ほどダウンロードした「g/melの低かったG_〇〇〇〇.pth」をパスを指定するので、私の場合「”model”:”C:\\mmvc_multi\\G_62000.pth”」となります
4.「”noise”:」は先ほど録音したノイズ音声なので「noise.wav」をパス指定するので、「”noise”:”C:\\mmvc_multi\\noise/wav”」となります。
バックスラッシュ「¥」は必ず画像のように2連続で入力してください。
この記事と同じように進めた場合パスが同じだと思うのでコピー欄を用意しますが、違う場合もあるので注意してください。
:より先をコピーして貼り付けてください
“json”:”C:\\mmvc_multi\\config.json” |
“model”:”C:\\mmvc_multi\\G_62000.pth” ※数字は自分のデータと同じに変えてください |
“noise”:”C:\\mmvc_multi\\noise.wav” |
22.「”others”: {」の書き換え
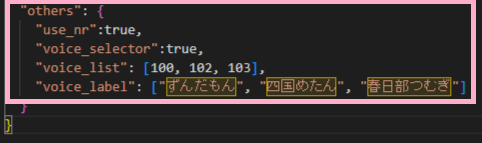
1.「”use_nr”」の「false」を「true」に書き換えてください。
2.「”voice_selector”」の「false」を「true」に書き換えてください。
3. 「”voice_list”」は同じように進めた場合は [100, 102, 103]と入力してください。
4.「”voice_label”」は同じように進めた場合は [“ずんだもん”, “四国めたん”, “春日部つむぎ”]と入力してください。
5.すべて完了したら保存してください。
23.「MMVC_Client」から「mmvc_client_GPU_v0.3.0.0」を開き「mmvc_client_GPU.exe」を開く
1.「MMVC_Client」から「mmvc_client_GPU_v0.3.0.0」を開き下の方にスクロールしたら「mmvc_client_GPU.exe」があるのでを開いてください。
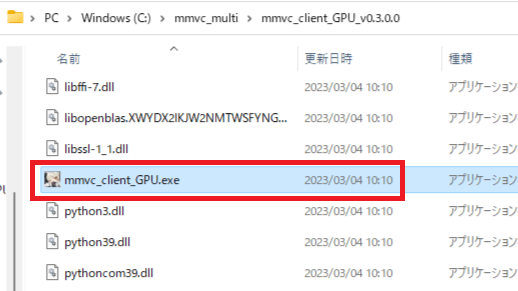
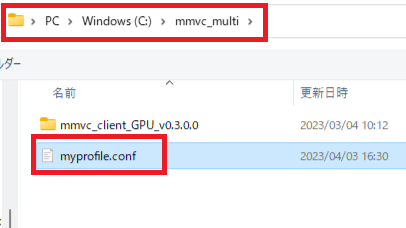
2.黒いウィンドウが出てきた後少し待つと、ファイルを選ぶウィンドウが出るので、「mmvc_multi」から「myprofile.conf」を選んでください。
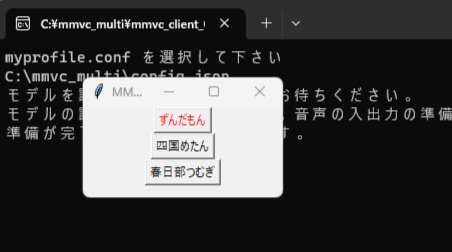
3.画像の様に「ずんだもん」「四国めたん」「春日部つむぎ」と表示されたボタンがでるので赤くなっているのが今変換している音声です。
24.Discord で使用できるように設定を変更し変換されてるか確認
Discord の音声設定の入力でデバイスは「CABLE Outpout」としてください。
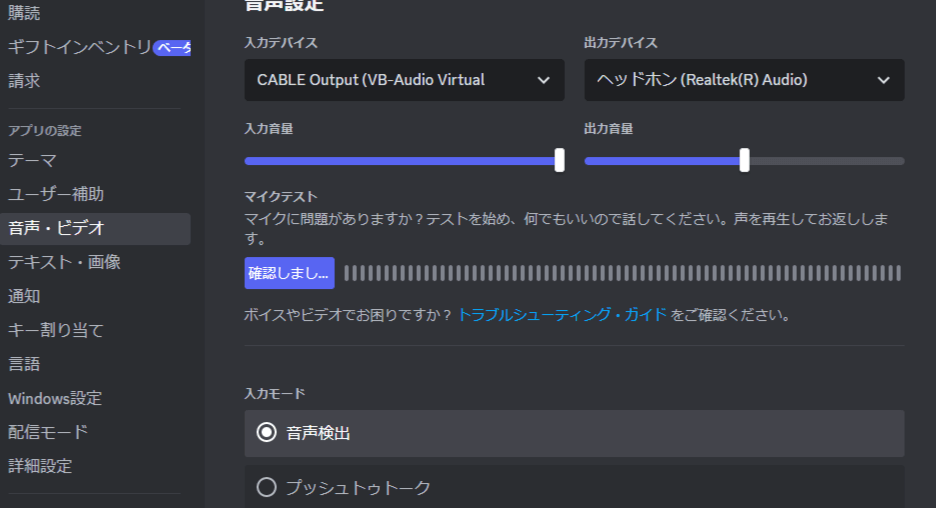
詳細設定も色々オンオフ切り替えて一番よく聞こえる設定をさがしてください。
まとめ
学習した音声の精度が低いと感じた場合は自分の録音した音声が良くない可能性が大きいので、面倒くさいですが録音をやり直すのがおすすめです。
また、ぜひ友達や配信でMMVCを使って楽しませてください。MMVCを導入したい方にはこの記事を紹介していただけるととても嬉しいです。

















